Sharing pengalaman lagi nih.
Ditahun 2017 saya (as a programmer) dan team mendevelop aplikasi web (app monolith dengan PHP) yang bakal diakses dari seluruh Indonesia. Setelah beberapa bulan aplikasinya pun jadi dan dipakai oleh banyak user. Hari ke hari, minggu ke minggu aplikasi berjalan tidak ada masalah.
Sampai 1 bulan kemudian data semakin banyak, trafik semakin gede dan mulailah muncul masalah. Aplikasinya jadi lemot diakses, user complain ‘ini aplikasi lemot sekali menghambat pekerjaan‘ dan pedasnya omongan user ‘cari programmer yang bener dong, jangan yang abal-abal, lemot kan aplikasinya‘ dan ada juga yang menuangkan kekesalannya dengankan menuliskan kalimat ‘f*** the system‘ dibalik pintu toilet. Wow sungguh super sekali (This is real story).
Memang sih ini salahnya programmer.. karena yang buat aplikasinya kan programmer? LOL
Dalam 1 minggu kita coba cari apa kendalanya di sistem, kenapa bisa lemot nih aplikasi? Sampai akhirnya ketemu juga masalah ada dimana. INDEXING. Yes masalah utamanya ada di indexing. Jadi kita ngelakuin SELECT .. WHERE ke kolom yang gak di INDEX dan itu banyak. Haha. Mungkin ada benarnya yang dibilang user, saat itu kita masih dilevel programmer abal-abal.
Akhirnya kita coba benahin indexing di DBnya (waktu itu pakai MySQL). Dan coba juga beberapa cara lain untuk mengoptimalisasi aplikasi supaya tidak lemot. Kita mulai upgrade skill kita sebanyak-banyaknya, belajar cara optimalisasi aplikasi dan mengimplementasikannya kedalam sistem.
Nah berikut ini adalah teknik-teknik optimalisasi yang sudah kita lakuin dari 2017 s/d 2023:
1. Tambahkan Index
Ngelanjutin dari pembahasan diatas, jadi kita tambahkan index pada kolom yang mengandung query where. Contoh:
SELECT order_no FROM order WHERE destination_code = '0201';Maka kolom destination_code harus di INDEX
CREATE INDEX idx_destination_code ON order (destination_code);Setelah itu percayalah walaupun ada banyak data, jika dijalankan query select diatas lagi, maka akan lebih cepat.
*Note: Jangan tambahkan INDEX pada semua kolom, karena akan berdampak pada performa INSERT/UPDATE. Tambahkan INDEX seperlunya saja pada kolom yang dianggap penting
2. Tambahkan Composite Index
Sama seperti INDEX pada nomor 1, cuma bedanya composite index ini adalah multiple column index. Saya kasih contoh
SELECT order_no FROM order WHERE origin_code = '2211' AND destination_code = '0201';Ada 2 kolom yang di where, maka agar lebih cepat querynya bisa ditambahkan composite index
CREATE INDEX idx_origin_destination ON order (origin_code, destination_code);*Note: tambahkan composite index ke kolom yang benar-benar diperlukan saja
3. Gunakan USE INDEX pada kasus tertentu
Saat kita menjalankan query SELECT ..WHERE ..JOIN, dibackground process sebenarnya mysql mencoba mengoptimalkan query kita, yaitu dengan mencarikan INDEX yang kira-kira optimal/tepat untuk digunakan. Setelah dapat INDEXnya mysql akan menjalankan querynya dengan menggunakan INDEX tersebut. Kita bisa cek proses dibelakangnya menggunakan EXPLAIN
EXPLAIN SELECT a.order_no FROM order AS a
JOIN mst_coverage AS b ON b.coverage_code = a.origin_code
WHERE a.create_date > '2023-01-01 00:00:00';Hasil dari EXPLAIN nanti akan ada kolom possible_keys dan key. Kita bisa cek pada kolom key, INDEX mana yang digunakan oleh mysql. Apakah sudah tepat atau tidak?
Terkadang INDEX yang digunakan mysql tidaklah tepat (salah INDEX), yang berakibat query kita jadi lemot. Nah untuk meng-slove problem tersebut, kita bisa tentukan sendiri INDEX mana yang mau kita gunakan. Sebagai contoh kita bisa sisipkan USE INDEX diquery join:
SELECT a.order_no FROM order AS a
JOIN mst_coverage AS b USE INDEX(idx_origin_code) ON b.coverage_code = a.origin_code
WHERE a.create_date > '2023-01-01 00:00:00';
Note: Penting disini untuk mendebug query kita menggunakan EXPLAIN. Untuk mengetahui kira-kira query kita sudah optimal belum?
Jika mau belajar mengenai EXPLAIN bisa langsung ke website mysqlnya disini https://dev.mysql.com/doc/refman/5.7/en/using-explain.html.
4. Perbaiki Query SELECT
Ini juga penting, jangan menyelect semua kolom pada query SELECT
SELECT * FROM order WHERE ...Jangan menggunakan asterisk (*) pada query SELECT, karena semua kolom akan dipanggil dan semakin banyak kolom yang dipanggil akan semakin lemot querynya. Harusnya kita select beberapa kolom saja sesuai kebutuhan, misal
SELECT order_no, origin_code FROM order WHERE ...5. Denormalisasi data
Adakalanya kita butuh denormalisasi daripada normalisasi. Denormalisasi adalah menggabungkan beberapa data yang ada pada beberapa tabel, menjadi 1 tabel. Tujuannya adalah untuk mempercepat query SELECT.
#Tanpa denormalisasi
+-----------------------+
mst_coverage
+-----------------------+
coverage_code
covarage_name
+-----------------------+
mst_item
+-----------------------+
item_code
item_name
+-----------------------+
order
+-----------------------+
order_date
origin_code
item_code
destination_codeUntuk mendapatkan item_name, origin_name dan destination_name kita harus melakukan 3x join
SELECT b.coverage_name AS `origin_name`, c.item_name, d.coverage_name AS `destination_name`
FROM order AS a
JOIN mst_coverage AS b ON b.coverage_code = a.origin_code
JOIN mst_item AS c ON c.item_code = a.item_code
JOIN mst_coverage AS d ON d.coverage_code = a.destination_code
WHERE a.order_date >= '2023-01-01'Semakin banyak JOIN akan semakin lemot querynya.
#Dengan denormalisasi
Daripada melakukan JOIN, kita taruh saja datanya di table order
+-----------------------+
order
+-----------------------+
order_date
origin_code
origin_name
item_code
item_name
destination_code
destination_nameKemudian ubah quernya menjadi
SELECT a.origin_name, a.item_name, a.destination_name
FROM order AS a
WHERE a.order_date >= '2023-01-01'Maka query akan jadi lebih cepat.
Note: Pastikan kalian menerapkan metode ini ke data-data yang jarang berubah. Karena metode ini akan menimbulkan redundancy data, inconsistency data dan size menjadi lebih besar (Intinya jadi sulit dimaintenance).
6. Ubah engine Database dari MyISAM ke InnoDB
Jangan gunakan engine MyISAM pada tabel yang memiliki banyak transaksi INSERT, karena performanya akan buruk. Lebih baik gunakan engine InnoDB untuk mempercepat transaksi INSERT. Jangan lupa juga untuk mengeset innodb_buffer_* pada konfigurasi MySQL. Set sebesar 70% dari total RAM yang tersedia. Gunakan MyISAM hanya pada tabel master saja, yang lebih banyak read datanya.
7. Gunakan Serverside Datatable
Gunakan metode serverside pada datatable untuk mengambil data sebagian saja / perpage. Akan lebih cepat loadnya ketika data sudah banyak, dibandingkan dengan metode clientside yang mengambil semua data.
8. Jangan gunakan COUNT() pada pagination datatable
Biasanya jika kita menampilkan data di datatable, si datatable akan menghitung total rownya ada berapa, baru kemudian dibuat paginationnya, baru setelah itu query lagi untuk mendapatkan datanya dan ditampilkan berdasarkan perpage. Jadi ada 2 query (query COUNT() untuk pagination dan query untuk get data)
SELECT COUNT(*) FROM order; // dapatkan total order lalu buat paginationnya
SELECT order_no, origin_name, destination_name FROM order LIMIT 0,10; // get datanyaIni gak akan jadi masalah kalau datanya cuma sedikit, tapi beda cerita kalau data sudah mencapai puluhan-ratusan juta maka akan lemot.
Solusinya batasi paginationnya. Jadi kita hilangkan query COUNT(), ganti dengan variable statis count misal 5000, artinya hanya ada max 5000 data yang ditampilkan. Misalkan perpage ada 10 data maka total page adalah 5000 / 10 = 500 page.
Jadi didatatable mesti ada yg dicustom scriptnya untuk mereplace query COUNT() menjadi variable statis.
9. Jangan gunakan query like %% pada kolom pencarian datatable
Masih didatatable, defaultnya ketika kita ingin mencari data melalui pencarian datatable, datatable akan menggenerate query like %% dan mencari ke semua kolom dengan like tersebut. Itu akan super super lemot jika datanya sudah besar.
SELECT order_no, origin_name, destination_name FROM order WHERE origin_address LIKE '%bandung%' OR origin_tlp LIKE '%8561%' OR destination_name LIKE '%jakarta%';Jadi ganti metodenya dengan hanya mencari data pada kolom tertentu saja. Jadi difrontend dan backend (script datatable) harus ada yang disesuaikan. Di frontend user harus memilih kolom mana yang mau dicari (ada option list), misal user memilih kolom ‘origin_address’, kemudian user memasukkan text yang mau dicari misal ‘bandung’, maka ketika mengklik tombol cari, backend akan menerima datanya dan menjalankan query pada kolom tersebut saja:
$column_name = $this->input->post('column_name');
$search_value = $this->input->post('search_value');
SELECT order_no, origin_name, destination_name FROM order WHERE $column_name LIKE '$search_value%';Jadi nama kolom dan search valuenya didapat dari hasil post dari clientside. Ada juga perubahan query LIKE diatas hanya menggunakan % pada akhir saja, fungsinya untuk mencari data dengan awalan dari $search_value saja agar query bisa lebih cepat. Atau lebih bagusnya lagi, hilangkan query LIKE dan ganti ke query sama dengan (=).
Note: Perlu diperhatikan, variable column_name dan search_value kita passing ke dalam query. Pastikan menggunakan query builder saat menggenerate query, supaya aman dari injeksi.
10. Ganti plugin export excel (xlsx) dari PHPExcel ke Spout
Bukan meremehkan, PHPExcel juga bagus untuk digunakan. Tapi ketika data sudah besar PHPExcel sering kena memory limit PHP (Allowed memory size of x bytes exhausted (tried to allocate x bytes). Sebenarnya bisa ditunning supaya bisa lebih cepat, tapi harus ada perbaikan sana sini. Dan ini perlu makan waktu, jadi kita putuskan untuk skip tunningnya.
Maka dari itu kita beralih ke Spout. Setelah kita ganti ke spout tidak terkena memory limit PHP. Setelah saya cari-cari kenapa spout lebih cepat adalah karena spout memiliki lebih sedikit fitur. Kalau di PHPExcel kita bisa gunakan fitur setAutoSize(true) *untuk mengeset ukuran kolom sesuai dengan panjang text, sementara di Spout tidak ada. Kesimpulan yang saya dapat, ternyata semakin banyak fitur yang digunakan untuk menggenerate file excel, semakin besar RAM yang dibutuhkan dan semakin besar juga temporary file XML yang diperlukan. Semakin besar file XMLnya semakin lama untuk dilakukan proses zipping menjadi file .xlsx. Akibatnya kita harus menunggu lebih lama saat mengexport data.
11. Export excel menjadi file .csv
Ini merupakan solusi lain jika kita tidak ingin menggenerate excel dalam format xlsx (karena mengkonsumsi lebih banyak RAM)
Kita bisa implementasikan export to .csv kedalam sistem, tapi harus diperhatikan juga dari sisi usernya. Usernya mau atau tidak? User biasanya akan ngeluh ketika mendownload report dalam bentuk .csv. Keluhannya ada 2 biasanya:
- File .csv nya kok gede sekali ukurannya? Laptop saya tidak kuat bukanya
- Ini setelah dibuka datanya kok berantakan ya? hanya 1 kolom memanjang kekanan. Harus di text to column dulu supaya datanya pecah jadi beberapa kolom. Wasting time sekali.
Jika user tidak ngeluh akan kedua hal tersebut, kita bisa implementasikan kedalam sistem.
Keuntungan export file menjadi .csv kita bisa lakukan stream ke client. Artinya data bisa didownload sedikit-sedikit sampai kelar. Dan ini menghemat resource RAM karena langsung stream dan bentuknya plaintext (tidak perlu ada proses zip zipan kaya xlsx, jadi menghemat waktu)
Namun perlu dicatat, file berektensi .csv ukurannya akan jauh lebih besar dibandingkan file .xlsx. Selain itu, ketika kita buka di excel harus di text to column dulu supaya datanya bisa kepecah jadi beberapa kolom.
12. Pisahkan server report dan server utama, beserta databasenya
Biasanya kalau aplikasi kita monolith semua module jadi 1 server. Termasuk module untuk download report. Kendalanya adalah ketika data semakin banyak dan traffic semakin besar, saat ada beberapa user sedang tarik data (download report), maka resource RAMnya akan kesedot kesana semua (karena data report yang didowload lumayan banyak 30 hari, jadi butuh RAM yang besar). Sehingga ini mengganggu transaksi utama, jadi banyak yang gagal INSERT.
Nah, lebih baik kita pisahkan antara download report dengan transaksi utama. Jadi download report punya server sendiri dan databasenya juga punya server sendiri (Jadi total butuh 2 server baru).
Nanti antara database utama dan database report dibuat master – slave replication. Database report akan bertindak sebagai slave yang akan mereplikasi data dari database utama. Jadi ketika ada user mendownload report akan connect ke server report, lalu ambil datanya dari database report (bukan database utama), jadi database utama tidak akan kena impact saat ada user menarik report. Kira-kira seperti ini gambarannya:
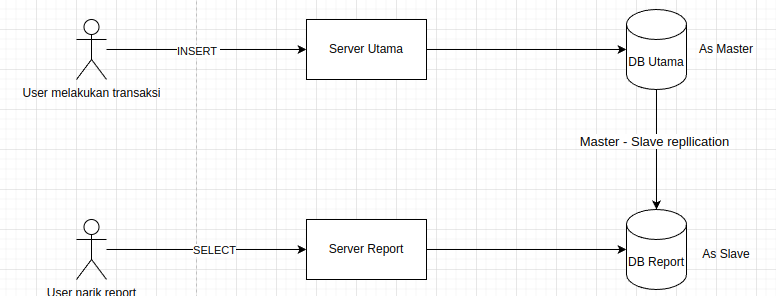
13. Menggunakan Auto Scaling
Jika aplikasi kalian berjalan di cloud, misal di AWS, GCP, dll. Maka bisa memanfaatkan fitur autoscaling.
Fungsi autoscaling adalah untuk men-scale (memperbanyak/memperkecil jumlah server aplikasi) sesuai demand/kebutuhan. Misal aplikasi kita sedang menerima traffic yang besar dan aplikasi yang sekarang sudah tidak sanggup lagi menghandle traffic, autoscaling akan otomatis menambahkan server aplikasi lainnya, jadi traffic yang baru akan dihandle oleh server aplikasi yang baru ini.
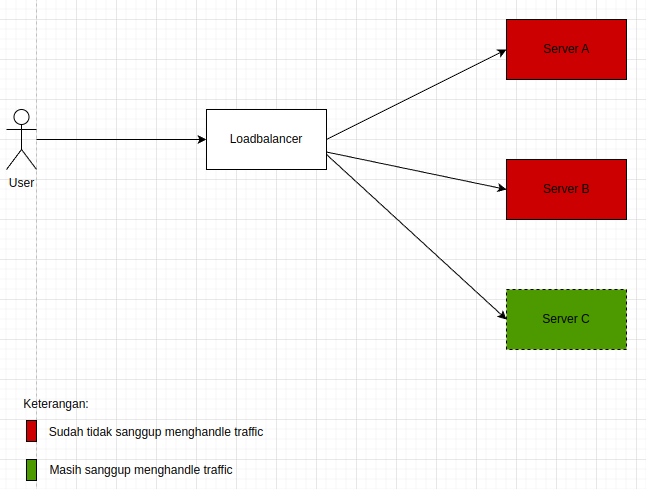
Penjelasan:
- Autoscaling akan membuat server baru (server C) ketika server A dan B sudah tidak sangggup lagi menghandle traffic. Biasanya autoscaling akan tertrigger ketika CPU usage atau RAM usage sudah mencapai batas yang ditentukan. Misal CPU usage pada autoscaling kita tentukan sebesar 80%, maka ketika server A atau server B sudah mencapai CPU 80%, maka autoscaling akan membuat server baru (server C).
- Setelah server C terbuat, traffic yang baru akan diarahkan ke server C oleh loadbalancer.
Jadi fitur autoscaling ini sangat disarankan diimplementasikan untuk menghandle traffic yang besar.
14. Ganti webserver dari Apache ke Nginx
Selanjutnya ganti apache ke nginx. Serius? Yes.
Apache akan lemot ketika berhadapan dengan traffic yang besar. Waktu itu saya setupnya menggunakan mode default (mod_prefork). Jadi setiap ada request masuk akan dibuatkan process baru oleh apachenya. Semakin banyak request masuk semakin banyak processnya, akibatnya pemakaian memory RAM dan CPU menjadi super high dan juga lemot. Sudah saya naikkan juga spek servernya dan setingan mod_preforknya, tapi sepertinya tidak berguna (karena saking banyaknya request masuk).
Akhirnya saya coba ke mode worker (mod_worker). Katanya sih dengan mod_worker bisa ngehandle concurrency yang tinggi / traffic yang tinggi. Tapi ketika diimplementasikan malah ngehang apachenya. Entah apa yang salah.
Frustasi dengan apache, akhirnya saya pindah ke nginx saja. Saya install dan implementasikan ke production, dan hasilnya wow. Nginx cuma butuh setengah resource dari spek server apache sebelumnya. Dan soal traffic saya coba pasang monitoringnya dengan grafana, dan tidak ada masalah soal response timenya. Client pun tidak ada yang complain soal lemot lagi.
15. Gunakan memcached atau redis
Gunakan memcached atau redis untuk menaruh data-data yang sifatnya jarang berubah dan sering diakses sama user ke RAM. Jadi ketika user membutuhkan data tersebut, cukup ambil datanya di RAM dan tidak perlu connect ke database. Ini akan menghemat koneksi kedatabase, karena buka koneksi ke database itu mahal. Dan juga kalau ambil data di RAM itu akan lebih cepat dibandingkan ambil data di storage.
Note: perlu dicatat, menggunakan RAM untuk caching data itu costnya lebih mahal ketimbang menggunakan storage. Jadi bijak-bijaklah dalam menggunakan memcached atau redis.
16. Menggunakan metode asynchronous pada case tertentu
Metode asynchronous terkadang diperlukan dalam sebuah aplikasi. Contoh disini saya mengimplementasikannya ke form pendaftaran. Jadi ketika ada user mendaftar dan mengklik tombol registrasi, user akan langsung mendapatkan response ‘berhasil registrasi’, padahal sebenarnya dibelakang layar sistem belum selesai mengirimkan email aktivasinya.
Jadi gunanya asynchronous disini adalah untuk mempercepat user saat proses registrasi. Selain itu dari sisi aplikasi berguna untuk mencegah terjadinya bottleneck jika ada banyak user yang mendaftar secara bersamaan (jadi proses kirim email dibuat asynchronous).
———————-
KESIMPULAN
Menghandle data banyak dan traffic yang besar bukan perkara mudah. Harus banyak yang dioptimalisasi mulai dari aplikasinya, databasenya, webservernya sampai dengan cloudnya.
Harus ada kolaborasi antara programmer, dba, devops/cloud engineernya supaya aplikasi bisa berjalan dengan baik bisa menghandle traffic yang besar.
—
Akhir kata, semoga artikel ini bermanfaat, see you!